
Summary of Basic C Knowledge
Summary of Basic C Knowledge
Conceptual Part
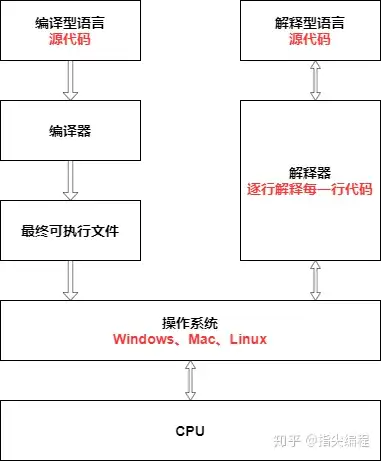
Interpreted vs Compiled Languages
Computers cannot understand high-level languages, nor can they directly execute them. Computers can only understand machine languages, so programs written in any high-level language must be converted into machine language, which is a set of binary instructions (0s and 1s), in order to be recognized and executed by computers.
Compiled Languages:
Compiled languages are a type of programming language that is implemented through a compiler. Unlike interpreted languages, which run code line by line via an interpreter, compiled languages use a compiler to translate the entire code into machine code before execution. In theory, any programming language can be either compiled or interpreted, depending on the context in which it is used (Wikipedia).
In general, programs written in compiled languages tend to execute faster because the code has already been precompiled into machine code and can be run directly. However, this also results in some disadvantages: compiled languages require a compile step before running the program, which typically increases the time spent developing and debugging programs. Unlike interpreted languages that can be run and debugged immediately after writing a small segment of code, compiled languages require more time and effort during development.
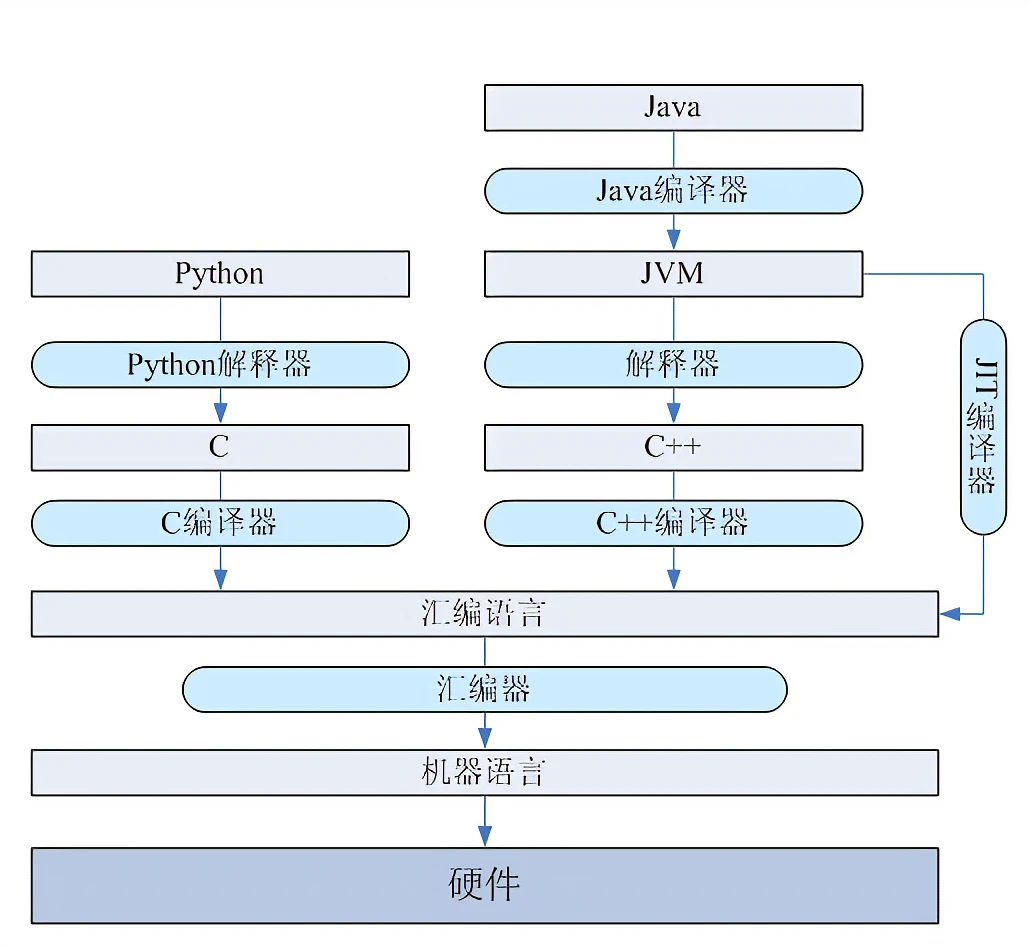
To improve the efficiency of compiled languages, Just-In-Time (JIT) Compilation has been developed, which blends the advantages of both compiled and interpreted languages. This technique first compiles the source code into bytecode, which is then interpreted and executed at runtime. Java and LLVM are prime examples of this technology.
Interpreted Languages:
Interpreted languages execute code line by line at runtime through an interpreter, without the need for pre-compiling the entire program into machine code, as is the case with compiled languages. Interpreted languages dynamically translate each line of code into machine code or precompiled subroutines during execution (Wikipedia).
In theory, any language can be implemented either as compiled or interpreted, depending on the application. Many languages, such as Lisp, Pascal, C, BASIC, and Python, have both interpreted and compiled implementations. Java and C# use a hybrid approach, compiling code into bytecode and then interpreting it at runtime.
| Type | Principle | Advantages | Disadvantages |
|---|---|---|---|
| Compiled Language | Translates all source code into machine code at once (usually as an executable file). | High execution speed once compiled, can run independently of the compiler. | Low portability, less flexible. |
| Interpreted Language | Translates and executes the source code line by line at runtime. | High portability, as the same code can be interpreted on different platforms. | Slower execution, less efficient. |
Interpreter vs Compiler
Compiler
- The compiler reads the source code and produces executable code.
- It translates code written in high-level language into instructions that the computer can understand.
- The compilation process is complex and takes time to analyze and process the program.
- The output is machine-specific binary code.
- A compiler is a program that reads high-level language programs, converts them into machine language or low-level language, and reports errors in the program.
Interpreter
- The interpreter converts source code line by line during execution.
- It fully translates a high-level program into machine code.
- It allows evaluation and modification of the program during execution.
- It takes less time for analysis and processing than a compiler.
- Programs run slower in comparison to compiled languages.
Note: Java is both compiled and interpreted. Java code is compiled into bytecode, which the JVM interprets into machine code at runtime.
| Interpreter | Compiler | |
|---|---|---|
| Process | 1. Write code 2. No file linking or machine code generation 3. Source statements are executed line by line during execution | 1. Write code 2. Compile to check syntax correctness 3. If no errors, compile source code into machine code 4. Link code files into an executable 5. Run the program |
| Input | Reads one line at a time | Reads the whole program |
| Output | Does not generate intermediate code | Generates intermediate object code |
| Execution | Compilation and execution happen simultaneously | Compilation is separate from execution |
| Storage | Does not store any machine code | Stores compiled machine code on the machine |
| Execution Speed | Slow | Fast |
| Memory Usage | Requires less memory, as no intermediate object code is created | Requires more memory due to object code creation |
| Error Detection | Errors are detected line by line during execution | All errors and warnings are shown during compilation |
| Example Languages | PHP, Perl, Python, Ruby | C, C++, C#, Scala, Java |
Data Types
In C, data types refer to a broad system used to declare different types of variables or functions. The type of a variable determines the amount of space allocated in memory and how the stored bit patterns are interpreted.
C types can be categorized as follows:
| No. | Type and Description |
|---|---|
| 1 | Basic Types: Arithmetic types, including integer and floating-point types. |
| 2 | Enumeration Types: Arithmetic types that allow for discrete integer values in the program. |
| 3 | Void Type: The void specifier indicates the absence of any value. |
| 4 | Derived Types: Includes pointer types, array types, structure types, union types, and function types. |
Array Types and Structure Types
Array types and structure types are collectively referred to as aggregate types. The type of a function refers to the type of the function’s return value. In the following sections, we will introduce the basic types, while other types will be explained in subsequent chapters.
Integer Types
The following table lists the storage size and value range details for standard integer types:
| Type | Storage Size | Value Range |
|---|---|---|
| char | 1 byte | -128 to 127 or 0 to 255 |
| unsigned char | 1 byte | 0 to 255 |
| signed char | 1 byte | -128 to 127 |
| int | 2 or 4 bytes | -32,768 to 32,767 or -2,147,483,648 to 2,147,483,647 |
| unsigned int | 2 or 4 bytes | 0 to 65,535 or 0 to 4,294,967,295 |
| short | 2 bytes | -32,768 to 32,767 |
| unsigned short | 2 bytes | 0 to 65,535 |
| long | 4 bytes | -2,147,483,648 to 2,147,483,647 |
| unsigned long | 4 bytes | 0 to 4,294,967,295 |
Note: The storage size of various types depends on the system architecture, with 64-bit systems being more common today.
Below is a comparison of storage size differences between 32-bit and 64-bit systems (also applicable to Windows):
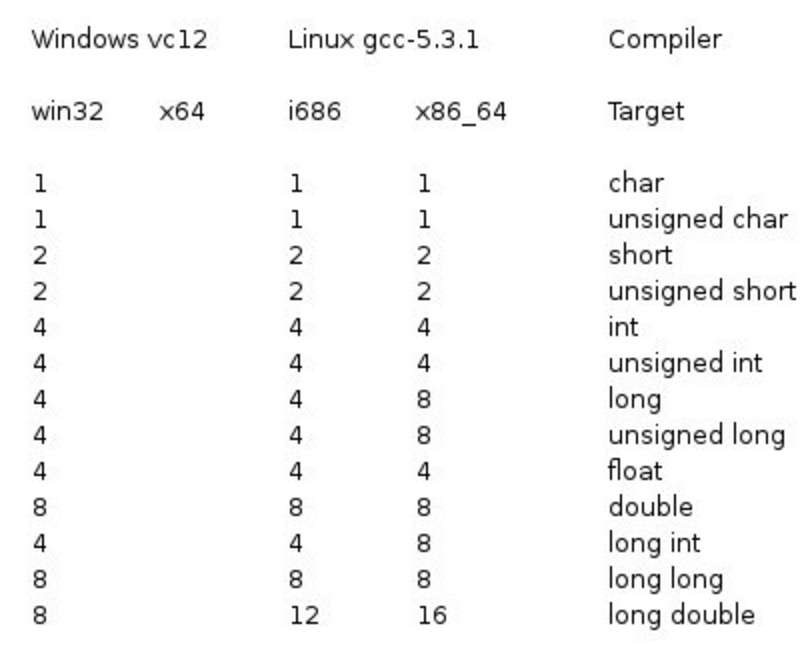
To determine the exact size of a particular type or variable on a specific platform, you can use the sizeof operator. The expression sizeof(type) returns the size in bytes of the object or type. The following example demonstrates how to get the size of the int type:
Example
1 |
|
%lu is used for printing 32-bit unsigned integers. For more details, refer to C Library Function - printf().
When compiled and executed on Linux, the program produces the following output:
1 | Storage size of int: 4 |
Floating-Point Types
The following table lists the storage size, value range, and precision details for standard floating-point types:
| Type | Storage Size | Value Range | Precision |
|---|---|---|---|
| float | 4 bytes | 1.2E-38 to 3.4E+38 | 6 significant digits |
| double | 8 bytes | 2.3E-308 to 1.7E+308 | 15 significant digits |
| long double | 16 bytes | 3.4E-4932 to 1.1E+4932 | 19 significant digits |
The header file float.h defines macros that provide these values and other details about the binary representation of real numbers in programs. The following example outputs the storage size, value range, and precision of the float type:
Example
1 |
|
%E is used to print single- and double-precision floating-point numbers in scientific notation. For more details, refer to C Library Function - printf().
When compiled and executed on Linux, the program produces the following output:
1 | Storage size of float: 4 |
void Type
The void type specifies that no value is available. It is typically used in the following three cases:
| No. | Type and Description |
|---|---|
| 1 | Functions returning void: Some functions in C do not return a value, or you can say they return void. The return type of such functions is void. For example, void exit (int status); |
| 2 | Functions with void parameters: Some functions in C do not accept any parameters. Such functions can take a void argument. For example, int rand(void); |
| 3 | Pointer to void: A pointer of type void * represents the address of an object but not its type. For example, the memory allocation function void *malloc(size_t size); returns a pointer to void, which can be cast to any data type. |
Data Structures
Arrays
An array is an ordered collection of elements that have the same data type.
Defining a String in Two Ways
1 | char *str = "Hello world!"; // This is a pointer to a string |
The difference between these two is that the first string is immutable because it resides in the constant memory section, while the second one is mutable and resides in the global static memory section or the stack.
Assigning Values to Array Elements
1 |
|
In this code, a loop is used to assign values to the array elements one by one.
In C, arrays cannot be assigned as a unit to another array, and aside from initialization, you cannot assign values using a list in braces.
The following code snippet demonstrates some invalid array assignments:
1 | /* Some invalid array assignments */ |
The last valid element in the oxen array is oxen[SIZE-1], so oxen[SIZE] and yaks[SIZE] both exceed the array bounds.
Array Boundaries
1 | char str[5] = "Hello"; // This is a dangerous string |
Although this string is syntactically correct, it poses a risk of array boundary overflow.
When you initialize an array, the compiler usually adds a '\0' character at the end to determine the array boundary. If the array size is insufficient to include '\0', a boundary overflow occurs.
This is a result of C’s principle of trusting the programmer. C does not perform boundary checking, which allows the program to run faster. The compiler does not need to capture all index errors because the array index value may not be known until runtime. Thus, to ensure safety, the compiler would need to add extra code to check each index at runtime, reducing the program’s speed. C assumes that programmers can write correct code, which improves performance. However, this trust can lead to index out-of-bounds issues.
Multidimensional Arrays
The simplest form of a multidimensional array is a two-dimensional array. Essentially, a two-dimensional array is a list of one-dimensional arrays. You declare a two-dimensional array with x rows and y columns as follows:
1 | type arrayName [ x ][ y ]; |
Here, type can be any valid C data type, and arrayName is a valid C identifier. A two-dimensional array can be thought of as a table with x rows and y columns. Below is a two-dimensional array with 3 rows and 4 columns:
1 | int x[3][4]; |

Speed Consideration
We know that accessing memory is much slower than accessing the CPU cache—by a factor of over 100. If the data the CPU needs is in the CPU cache, performance can improve significantly. When the data is in the CPU cache, this is called a cache hit. The higher the cache hit rate, the better the performance, and the faster the CPU runs.
The question then becomes: How can we write code that maximizes CPU cache hit rates?
As mentioned earlier, L1 cache is usually split into data cache and instruction cache. This is because the CPU processes data and instructions separately. For example, in the operation 1+1=2, the + is the instruction and is placed in the instruction cache, while the input 1 is placed in the data cache.
Thus, we need to consider data cache and instruction cache separately when optimizing cache hit rates.
How to Improve Data Cache Hit Rate?
When traversing a two-dimensional array, consider the following two ways to access the array. Although the results are the same, which do you think is more efficient? Why?
Testing shows that accessing the array with array[i][j] (form 1) is several times faster than accessing it with array[j][i] (form 2).
The reason for this large performance gap lies in how the two-dimensional array array is stored in memory, which is contiguous. For example, if the array’s length is N, and its memory layout is sequential, the elements are arranged as follows:
When accessing elements in form 1 with array[i][j], the memory layout matches the access pattern. When the CPU accesses array[0][0], it loads the next 3 elements into the CPU cache. As the CPU accesses the next 3 elements, they are already in the cache, resulting in a high cache hit rate. Since the data is found in the cache, there is no need to access memory, greatly improving performance.
Accessing Arrays with array[j][i]
If you access a two-dimensional array with array[j][i], the access pattern is discontinuous, as shown below:
As you can see, the access pattern jumps rather than follows a sequential order. When N is large, accessing array[j][i] does not allow array[j+1][i] to be loaded into the CPU cache as well. Since array[j+1][i] is not in the CPU cache, it has to be fetched from memory. This discontinuous, jumping access pattern cannot fully leverage the CPU cache, leading to lower performance.
CPU Cache Line Size
When the CPU accesses memory and the data is not in the CPU cache, it loads a block of data, typically 64 bytes (the size of the CPU cache line), from memory into the CPU cache. You can check the cache line size in Linux by looking at the coherency_line_size configuration.
For example, when accessing array[0][0], the CPU will read a block of 64 bytes, which is enough to store array[0][0]~array[0][15]. Since array[i][j] accesses the array sequentially, it aligns with how the data is stored in memory. This makes it possible to use the CPU cache more effectively and improve performance significantly compared to the jumping access pattern of array[j][i].
Therefore, when traversing arrays, accessing elements in memory layout order can significantly improve performance by leveraging the CPU cache.
Pointers
The Nature of Pointers
When you define a variable in C, you are essentially requesting a block of memory to store it. If you want to know where exactly the variable is stored, you can use the & operator to obtain the variable’s address. This address is the starting address of the memory block where the variable is stored, which is the pointer.
You can define a pointer like this:
1 | int *pa = &a; |
Here, pa stores the address of the variable a, and we call pa the pointer to a.
Why Do We Need Pointers?
One might ask: Why do we need pointers? Can’t we just use variable names?
Yes, we can use variable names, but they have limitations.
The Essence of Variable Names
A variable name is simply a symbolic representation of an address. Variables make programming easier for humans, but computers don’t understand variable names—they only know addresses and instructions.
When you look at the assembly code generated after compiling C programs, you’ll notice that variable names disappear, replaced by abstract addresses. The compiler maintains a mapping that translates variable names to their corresponding addresses, allowing the program to read and write to these addresses.
For example, the compiler might maintain a table like this:
1 | a | 0x7ffcad3b8f3c |
This mapping allows the program to interact with memory locations using variable names in the code.
The Necessity of Pointers
Consider the following scenario:
1 | int func(...) { |
Suppose we want func to modify the variable a in the main function. Inside main, you can directly access and modify a using its variable name. However, in func, a is not visible.
To solve this, you can pass the address of a to func:
1 | int func(int *address) { |
This way, func can access and modify a through its address.
Using int * for Pointers
The compiler needs a way to differentiate between an int value and a variable’s address. If you simply store an address in a regular int variable, it becomes difficult for the compiler to know if it’s dealing with a regular integer or an address.
By defining a pointer as int *, it explicitly tells the compiler that this variable holds an address of an int type. This type definition allows the compiler to perform type checks and prevent certain types of errors at compile time.
This is the necessity of pointers.
In fact, every language has this requirement, but many languages for the sake of safety put a layer of restrictions on pointers, wrapping them into references.
Many people naturally accept pointers when learning, but I hope this lengthy explanation gives you some insights.
At the same time, here are a few minor questions to think about:
Since the essence of pointers is just the starting address of a variable in memory, which is essentially an int type integer:
Why do we need different types of pointers, such as
int*orfloat*? Do these types affect the information stored in the pointer itself?When do these types come into play?
Dereferencing
The above questions lead to the concept of pointer dereferencing.
If pa stores the memory address of the variable a, how do we retrieve the value of a using that address?
This operation is called dereferencing, and in C, you can dereference a pointer using the * operator. For example, *pa will give you the value of a.
We know that a pointer stores the starting address of a variable in memory, but how does the compiler know how many bytes to fetch starting from this address?
This is where the pointer type comes into play. The compiler determines how many bytes to read based on the type of the element the pointer refers to.
For example, if it’s an int pointer, the compiler will generate instructions to fetch 4 bytes. For a char pointer, it will fetch just 1 byte, and so on.
Here’s a memory illustration of pointers:
pa is a pointer variable, and it also occupies a block of memory. Inside this block is the memory address of a. When dereferencing, the compiler will fetch 4 bytes from the starting address of a and interpret them as an int.
Applying the Concept
Although this might seem simple, it is key to deeply understanding pointers.
Let’s look at a couple of examples to clarify:
For instance:
1 | float f = 1.0; |
Can you explain what happens to the variable f at the memory level in this process? What’s the value of c? Is it 1?
Actually, nothing changes for f at the memory level.
Here’s the memory layout:
Assuming this is the bit pattern of f in memory, this process extracts the first two bytes and interprets them as a short, then assigns the result to c.
Here’s the detailed breakdown:
&fobtains the starting address off.(short*)&fdoesn’t change anything in memory. It simply interpretsfas if it were ashort.
Finally, when you dereference *(short*)&f, the compiler extracts the first two bytes and interprets them according to short encoding, assigning the result to the c variable.
In this process, the bit pattern of f doesn’t change. The only thing that changes is how the bits are interpreted.
Clearly, c will not be 1. You can compute the actual value yourself.
Now, what about this?
1 | short c = 1; |
Here’s a diagram of the situation:
The process is similar, but here we might run into issues.
(float*)&c treats the memory of c as if it were a float. The problem is that c is a short, which occupies only 2 bytes. The compiler will try to fetch 4 bytes starting from c‘s address, but this would access memory beyond c‘s allocated space, potentially causing out-of-bounds access.
If you are only reading, this might not immediately cause an issue. But if you try to write to this memory, for example:
1 | *(float*)&c = 1.0; |
This could lead to a core dump due to memory access violations.
Moreover, even if no error occurs, this operation would corrupt the memory, possibly overwriting the contents of adjacent variables, which could introduce hidden bugs.
If you’ve understood all this, you will handle pointers more confidently and skillfully.
 wechat
wechat alipay
alipay





