
The Life of a C Program
Have you ever wondered: after typing code in a C/C++ IDE, you only need to click the Compile and Run button and wait a few seconds to generate an executable program. But what exactly happens in the process of compiling and running? How does a .c/.cpp source file become an .exe (Windows) executable file?
After reading this article, you’ll have a clear answer. :)
In simple terms, the entire process is divided into four stages: Pre-processing, Compilation, Assembly, and Linking. As shown in the figure below (from the book CSAPP):

Note: Source program, modified source program, and assembly program are text files, while relocatable object program and executable object program are binary files.
It might seem like the explanation could stop here, since the entire process has been covered, right? However, if I were to end here, this article wouldn’t be very valuable. So, let’s dive deeper into each of the four stages!
Pre-processing
First, we’ll prepare a simple Hello World program, named main.c.
1 |
|
In the pre-processing phase, the pre-processor (cpp) modifies the original C program based on lines that start with the character #.
- For example,
#include <stdio.h>includes the contents of the stdio.h header file into the program text. - For example,
#define info "Hello, world\n"replaces the macro info with the string"Hello, world\n"(although we wouldn’t usually write it this way, it’s just for illustration). - Additionally, comments like
// A simple program.are removed.
The pre-processing directly manipulates the source file (without worrying about syntax rules), and generates another C program, usually with the .i file extension.
On Linux (I’m using Ubuntu), we can use the gcc -E main.c -o main.i command to get the pre-processed C program main.i. Below is a portion of it (the full file has over 800 lines), where you can clearly see: the header file is included, info is replaced, comments are removed, and special markers are added to indicate the origin of each line, so the compiler can use them to generate meaningful error messages.
1 | # 1 "main.c" |
Compilation
In the compilation phase, the compiler (cc1) translates the C program main.i into an assembly language program main.s.
- It checks for syntax errors in the C program.
- Translates the file into intermediate code, which is assembly language.
- Optionally optimizes the intermediate code for better performance.
We can use gcc -S main.i -o main.s to generate the assembly program main.s. Below is a snippet:
1 | .file "main.c" |
For example, the instruction pushq %rbp describes a low-level machine language instruction. Assembly language is useful as it provides a common output language for different compilers of various high-level languages—whether C or Fortran, they generate the same assembly language output.
Assembly
In the assembly phase, the assembler (as) translates main.s into machine language instructions, packaging these instructions into a format called a relocatable object file, and saving the result in the object file main.o (in Windows, it would be xx.obj, while in Linux, it’s xx.o). main.o is a binary file; if you open it with a text editor, you’ll see a bunch of garbled symbols.
We can use the gcc -c main.s -o main.o command to obtain the relocatable object file main.o, which looks something like this:
1 | LF>?@@ |
As expected, it’s a pile of gibberish.
Linking
In our main.c program, we use the printf function, which is provided by the standard C library included with every C compiler. This function exists in a precompiled object file called printf.o.
The job of the linker (ld) is to merge the required object files, such as main.o and printf.o, to create an executable file that can be loaded into memory and executed by the system.
In practice, when we use the command gcc main.c -o main, it generates the executable file—on Windows, this would be an .exe file, while on Linux, it’s usually an executable file named a.out by default. However, we used -o to customize the output file name.
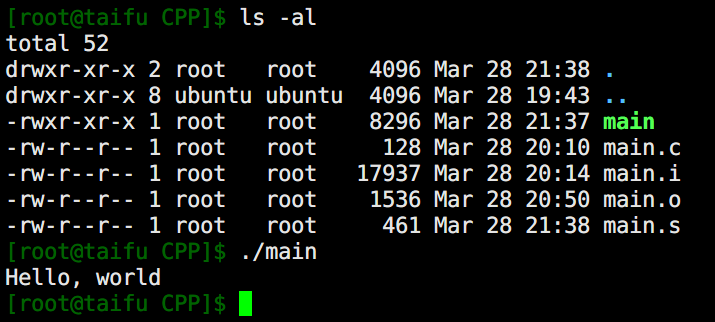
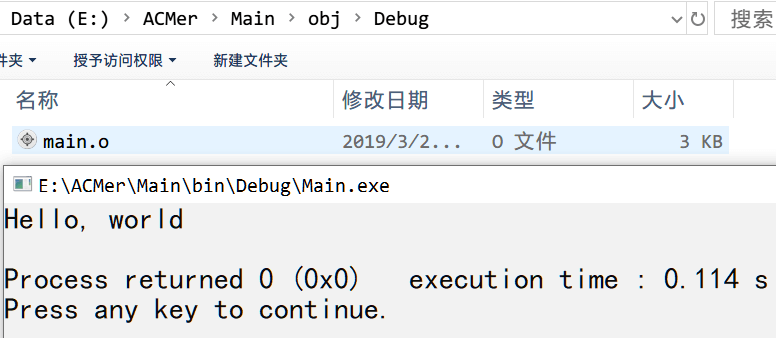
That’s the entire compilation process! Do you understand it now?
By the way
By the way, do you know the difference between compiled languages (C/C++) and interpreted languages (Python/Java)?
Here’s a fun explanation I found from an anonymous user on Zhihu.
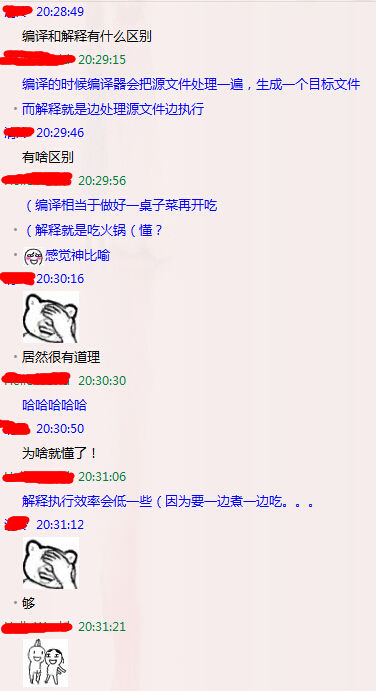
It’s a vivid description, and for more detailed explanations, you can refer to this blog by Katulus and this blog by jack-zhu. Below is another helpful image.
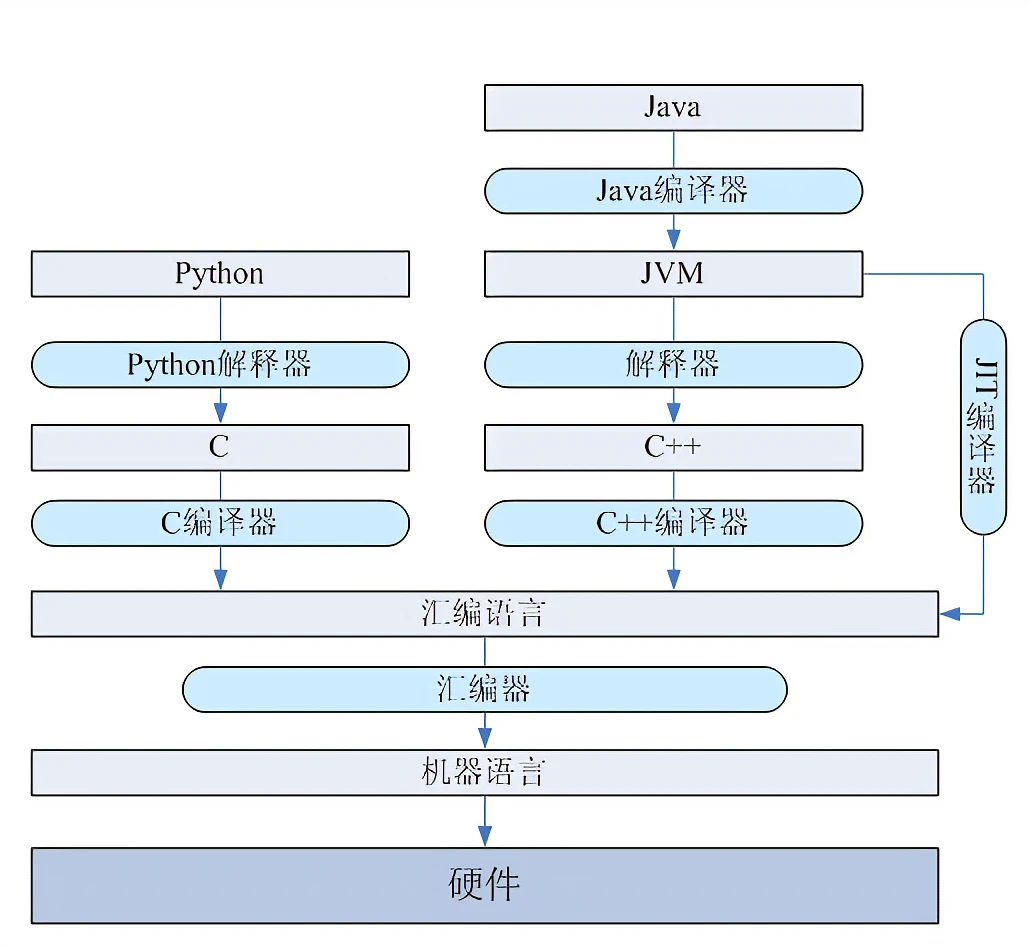
By the way 2
There’s another surprise!
For detailed explanations of the relationships between .obj, .lib, .dll, .exe files in Windows, and .o, .a, .so files in Linux, you can refer to Oldpan‘s blog. It’s well-explained.
In short, .obj is the relocatable object program we obtained in the assembly phase, .lib is a library file used for static linking, and .dll is a library file for dynamic linking. .lib and .dll are collections of multiple .obj files, with .lib needed during the compilation phase and .dll needed during runtime.
In Linux, .o corresponds to Windows’ .obj, .a corresponds to .lib, and .so corresponds to .dll.
 wechat
wechat alipay
alipay







